Neural Network Divorce Prediction Prevention Strategies
Data Collection and Feature Engineering for Neural Network Training
Data Collection Strategies
Collecting high-quality data forms the bedrock of successful machine learning initiatives. Without meticulously curated datasets, even the most sophisticated algorithms can produce unreliable results. Professionals must establish clear protocols for data acquisition, emphasizing both quantity and quality. The process involves verifying source credibility, cross-checking information, and documenting every step to ensure full traceability.
Various methodologies exist for gathering information - from structured surveys to automated web crawlers. Selection depends entirely on project requirements and data characteristics. Maintaining detailed records of collection processes isn't just good practice; it's what separates amateur efforts from professional-grade machine learning workflows.
Feature Engineering Techniques
Transforming raw inputs into meaningful predictors represents one of the most creative aspects of machine learning. Data scientists employ numerous techniques to extract maximum predictive power from available information. Feature engineering remains highly context-dependent - what works perfectly for one dataset might fail completely for another. The process often involves identifying non-obvious relationships and creating composite metrics that capture complex patterns.
Handling Missing Data
Incomplete datasets present significant challenges for model development. Choosing how to address missing values requires careful consideration of the potential impact on model integrity. Some situations call for simple imputation, while others necessitate sophisticated reconstruction algorithms. The decision should account for both statistical implications and the practical realities of the dataset's intended use.
Proper handling of data gaps can mean the difference between a model that performs adequately and one that delivers exceptional results. Data scientists must weigh the trade-offs between different approaches, considering factors like dataset size and the nature of the missing information.
Data Preprocessing Steps
Before data can feed neural networks, it must undergo thorough preparation. This includes standardization procedures, outlier treatment, and format conversions. Each step serves to enhance data quality and improve model performance. The preprocessing phase often consumes significant time but pays dividends in model accuracy.
Data Validation and Quality Assurance
Rigorous validation protocols ensure machine learning models operate on reliable foundations. Implementing comprehensive quality checks throughout the data pipeline isn't optional - it's fundamental to producing trustworthy results. This involves systematic error detection, consistency verification, and continuous monitoring.
Quality assurance extends beyond technical checks to encompass the entire data lifecycle. From initial collection through final analysis, maintaining data integrity requires constant vigilance and well-defined procedures.
Developing and Training the Neural Network Model
Data Preparation for Neural Network Training
The transformation from raw data to model-ready format involves multiple critical steps. Cleaning processes remove anomalies and inconsistencies that could skew results. Feature engineering extracts maximum predictive value, while normalization ensures all inputs contribute appropriately to the learning process.
Creative feature development can uncover hidden relationships within the data. For instance, financial stress indicators might combine income, debt, and spending patterns into composite metrics. Each transformation demands careful evaluation to avoid introducing unintended biases or distortions.
Model Selection and Architecture Design
Choosing the right neural network structure requires balancing complexity with practical constraints. Simpler architectures often outperform overly complex ones, especially with limited training data. The selection process should consider both current needs and potential future scaling requirements.
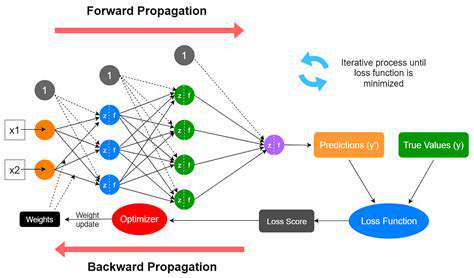
Training the Neural Network Model
The training phase represents where theory meets practice. Optimization algorithms adjust internal parameters to minimize prediction errors. Monitoring multiple performance metrics provides crucial feedback for tuning the learning process. Effective training requires patience and careful adjustment of learning parameters.
Evaluating Model Performance
Comprehensive evaluation separates promising models from truly effective ones. Proper validation techniques prevent overfitting and ensure generalizability. Performance metrics should address both overall accuracy and specific use case requirements. Visualization tools can reveal patterns that raw numbers might overlook.
Deployment and Maintenance of the Model
Transitioning from development to production introduces new challenges. Models require ongoing monitoring and periodic updating to maintain accuracy as real-world conditions evolve. The deployment strategy should include robust performance tracking and clear protocols for model refreshment.
Implementing Early Intervention Strategies Based on Predictions
Early Intervention Strategies for Enhanced Outcomes
Timely support systems can dramatically improve developmental trajectories. Early identification of challenges allows for more effective and less intensive interventions. Multidisciplinary teams bring diverse perspectives to assessment and planning processes.
Customized approaches account for individual differences in learning styles and needs. Continuous monitoring ensures interventions remain appropriately targeted as children develop and change. The most effective programs combine professional expertise with family involvement.
Key Components of Effective Early Intervention Programs
Successful initiatives integrate multiple developmental domains into cohesive support plans. Family education components empower caregivers to reinforce therapeutic strategies. Evidence-based practices provide reliable frameworks for intervention design.
Program flexibility allows for adjustments based on ongoing assessment results. Support networks extend beyond formal services to include community resources. Comprehensive programs address both immediate needs and long-term developmental goals.
Ethical Considerations and Future Research Directions

Transparency and Accountability
Clear documentation of methodologies builds trust in analytical processes. Decision-making systems should incorporate mechanisms for challenge and review. Responsibility structures must align with potential impacts of automated decisions.
Data Privacy and Security
Protective measures must evolve alongside technological advancements. Privacy safeguards should balance utility with individual rights protections. Regulatory compliance represents the minimum standard, not the ultimate goal.
Bias Mitigation and Fairness
Systematic bias detection requires ongoing attention throughout model lifecycles. Diverse development teams bring essential perspectives to fairness considerations. Impact assessments should examine both intended and unintended consequences.
Impact Assessment and Stakeholder Engagement
Comprehensive evaluation frameworks capture multidimensional effects. Community consultation enhances the relevance and appropriateness of data applications. Feedback mechanisms should facilitate continuous improvement.
Responsible Innovation and Societal Impact
Technology development must consider broader societal implications. Public education initiatives promote informed discussions about data applications. Ethical frameworks should guide innovation toward beneficial outcomes.
Read more about Neural Network Divorce Prediction Prevention Strategies












Hot Recommendations
- AI for dynamic inventory rebalancing across locations
- Visibility for Cold Chain Management: Ensuring Product Integrity
- The Impact of AR/VR in Supply Chain Training and Simulation
- Natural Language Processing (NLP) for Supply Chain Communication and Documentation
- Risk Assessment: AI & Data Analytics for Supply Chain Vulnerability Identification
- Digital twin for simulating environmental impacts of transportation modes
- AI Powered Autonomous Mobile Robots: Enabling Smarter Warehouses
- Personalizing Logistics: How Supply Chain Technology Enhances Customer Experience
- Computer vision for optimizing packing efficiency
- Predictive analytics: Anticipating disruptions before they hit