Neural Network Child Name Popularity Predictors
Data Collection and Cleaning
Comprehensive data acquisition forms the essential foundation for any neural network implementation. In analyzing naming trends, this necessitates compiling historical naming records including temporal frequency distributions. Potential data sources encompass governmental archives, demographic surveys, and digital registries. Data integrity during collection proves critical, as incomplete datasets can substantially compromise model reliability.
Following acquisition, rigorous data cleansing becomes imperative. This phase addresses data anomalies including missing entries, statistical outliers, and formatting inconsistencies. Name variations (including hyphenation differences or diminutive forms) require standardization to ensure analytical consistency. Text normalization procedures, such as case unification, further enhance data uniformity for neural network processing.
Feature Engineering for Predictive Modeling
Effective feature transformation represents a pivotal step in data preparation. For naming trend analysis, potential predictive features might include temporal markers, gender associations, onomastic characteristics, cultural derivations, and phonetic trends among similar names. Strategic feature selection directly influences model learning efficacy, requiring careful consideration of predictive relevance.
Quantitative representation of naming frequency through scaled metrics enhances model interpretability. Temporal features benefit from categorical encoding to capture chronological patterns, while cultural derivations may employ one-hot encoding to represent diverse influences affecting naming preferences.
Data Transformation and Scaling
Data standardization ensures compatibility with neural network architectures. This process may involve categorical-to-numerical conversion, value normalization within defined ranges, or distribution adjustments to achieve feature parity. Proper scaling prevents feature dominance, ensuring balanced contribution to the learning process.
Implementation of Z-score normalization represents a common standardization approach, centering features around zero mean with unit variance for optimal neural network performance.
Data Splitting and Validation Strategies
Strategic dataset partitioning into training, validation, and testing subsets enables comprehensive model evaluation. The training subset facilitates parameter optimization, while the validation set guides architectural refinement to prevent overfitting. The testing subset provides the ultimate performance assessment on novel data. Appropriate partitioning strategies ensure reliable generalization metrics.
Stratified sampling techniques maintain proportional class representation across subsets, particularly crucial for imbalanced datasets where certain categories demonstrate limited representation.
Handling Imbalanced Datasets (if applicable)
Dataset analysis should evaluate categorical distribution parity, particularly regarding gender-specific naming trends. Imbalanced scenarios necessitate corrective measures including minority class oversampling, majority class undersampling, or algorithmic compensation techniques. Balanced representation ensures equitable model learning across all categories, preventing predictive bias toward predominant classes.
These methodological considerations collectively contribute to developing robust predictive models capable of accurate naming trend forecasting across diverse demographic segments.
Training and Validation: Ensuring Robust Predictions
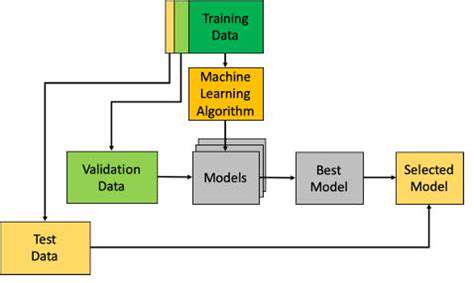
Training Data: The Foundation
High-quality training datasets constitute the fundamental building blocks of effective machine learning models. These curated collections provide the exemplar patterns that shape model behavior and predictive accuracy. Dataset quality attributes—including precision, completeness, and consistency—directly determine model generalization capabilities.
Representative sampling across demographic spectrums prevents predictive bias, while balanced category representation ensures equitable learning across all classification targets. These considerations prove particularly relevant in naming trend analysis where cultural and temporal factors significantly influence outcomes.
Validation Data: Assessing Performance
Validation datasets serve as the proving ground for model generalization capacity. By evaluating performance on previously unseen data samples, validation procedures identify potential overfitting scenarios where models demonstrate excellent training performance but poor practical applicability. This iterative validation process enables precise model calibration, optimizing real-world predictive accuracy.
Validation Techniques: Methods and Metrics
Advanced validation methodologies like k-fold cross-validation enhance evaluation robustness by mitigating partition-specific biases. Performance metrics including accuracy rates, precision scores, recall percentages, and F1 measurements provide multidimensional assessment of model effectiveness. Comprehensive metric analysis informs strategic model refinement, ensuring alignment with specific application requirements.
Overfitting and Underfitting: Common Pitfalls
Model optimization requires careful navigation between overfitting and underfitting extremes. Overfit models exhibit excessive training data specialization, while underfit models demonstrate inadequate pattern recognition. Architectural balance represents the key to optimal performance, achieved through careful hyperparameter tuning and regularization techniques.
Data Preprocessing: Preparing the Data
Thorough data preprocessing establishes the foundation for successful model training. This phase addresses data quality issues through missing value imputation, categorical encoding, and feature scaling. Meticulous preprocessing significantly enhances subsequent model performance, though often overlooked in favor of more glamorous modeling stages.
Data Augmentation: Expanding the Training Set
Data augmentation techniques artificially expand training datasets, particularly valuable for limited data scenarios. Techniques including synthetic sample generation, feature perturbation, and strategic sampling variations enhance model robustness. Augmentation strategies prove especially beneficial for niche naming trend analysis where historical records may be sparse.
Evaluation Metrics: Measuring Success
Metric selection should align with specific application requirements, considering operational tradeoffs between precision and recall, or accuracy versus interpretability. Context-aware metric selection ensures practical model utility, particularly in scenarios where prediction costs vary significantly between false positives and negatives.
Beyond Popularity: Exploring Other Factors
Cultural Influences on Naming Trends
Cultural dynamics exert profound influence on naming conventions, with globalized media exposure introducing diverse naming traditions to broader audiences. This cultural cross-pollination frequently manifests in the adoption of historically or geographically significant names, reflecting evolving societal values. Religious traditions similarly maintain strong naming influences, with faith-specific names demonstrating remarkable intergenerational persistence across devout communities.
Socioeconomic Factors and Naming Preferences
Economic circumstances subtly shape naming preferences, with resource availability influencing name commonality. Educational attainment similarly correlates with naming conventions, as higher education levels often associate with more deliberate naming strategies. These socioeconomic dimensions add nuanced layers to naming trend analysis, complementing pure popularity metrics.
The Impact of Celebrity and Media on Naming Choices
High-profile individuals and media representations significantly sway naming trends, with distinctive celebrity baby names frequently sparking broader adoption. Entertainment media similarly introduces novel naming options to mainstream consciousness. This media-driven influence represents a critical consideration when interpreting neural network predictions of naming popularity trajectories.
Read more about Neural Network Child Name Popularity Predictors












Hot Recommendations
- Digital Twin for Optimized Energy Consumption in Warehouses
- Advanced Robotics for E commerce Returns Processing
- Data Security in the Cloud for Supply Chain Compliance
- Building Trust: Enhancing Brand Reputation with Supply Chain Transparency
- The Impact of AI on Supply Chain Workforce Productivity
- The Future of AI in Supply Chain Optimization Algorithms
- Digital twin for simulating product delivery scenarios
- Blockchain for supply chain traceability in fashion
- Enhancing Risk Mitigation: Generative AI for Proactive Supply Chain Management
- Robotics for automated goods to person picking systems