Data Integration Challenges in Mergers & Acquisitions for Supply Chains
The Complexities of Data Integration Post-Merger
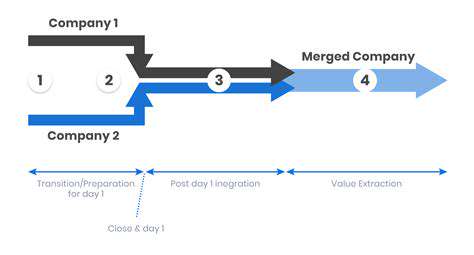
Data Integration Challenges
Data integration, while crucial for modern businesses, presents a multitude of complexities. These challenges arise from the diverse formats and structures of data sources, making it difficult to combine disparate information into a cohesive whole. Data silos, often a result of departmental data isolation, can hinder the flow of accurate and timely information across the organization. This fragmented data landscape can create significant obstacles to insightful analysis and informed decision-making.
Furthermore, the sheer volume and velocity of data generated today demand sophisticated integration solutions. Traditional approaches may struggle to handle this massive influx of information, potentially leading to bottlenecks and delays in data processing. Ensuring data quality and accuracy across various systems is another significant hurdle. Discrepancies in data formats, inconsistencies in naming conventions, and missing values can all lead to inaccurate insights and flawed decisions.
Technical Implementation Hurdles
Implementing data integration solutions often involves navigating complex technical hurdles. Choosing the right tools and technologies to connect various data sources can be a daunting task, requiring a deep understanding of the different platforms and protocols involved. Integrating legacy systems with modern platforms can also pose significant technical challenges, requiring careful planning and execution. Data transformation and mapping are essential steps in the process, and getting these steps right can be tricky, especially when dealing with diverse data types and structures.
Data Governance and Security
Data governance and security are critical aspects of successful data integration. Establishing clear policies and procedures for data access, use, and management is essential to ensure data integrity and compliance with regulations. Robust security measures are crucial to protect sensitive data from unauthorized access and breaches. This includes implementing encryption, access controls, and regular security audits.
Maintaining data quality throughout the integration process is paramount to ensure reliable insights. Implementing data validation rules and quality checks can help to identify and correct errors or inconsistencies in the data. Data governance frameworks need to be established to ensure data is used ethically and responsibly.
Cost and Resource Allocation
Data integration projects often involve significant financial investments. Assessing the total cost of ownership, including software licenses, hardware requirements, and personnel costs, is essential for effective budgeting and resource allocation. Careful planning and resource allocation are key to successful completion of the project. Determining the required expertise and skills within the organization is critical to ensure that the project is effectively managed and implemented.
Furthermore, integrating data from multiple sources can lead to unexpected costs related to data cleansing, transformation, and validation. Efficient project management practices are therefore essential to control costs and ensure timely completion.
Project Management and Communication
Effective project management is critical for successful data integration. Clear communication channels between stakeholders, including IT teams, business users, and data analysts, are essential to ensure alignment on project goals and expectations. Establishing a robust communication plan is crucial to ensure that all stakeholders are kept informed and engaged throughout the project lifecycle.
Managing timelines and deliverables effectively is essential to avoid delays and ensure that the project stays on track. Adequate training and support for users are necessary to ensure that they can effectively utilize the integrated data.
Addressing Data Quality Issues for Enhanced Visibility
Understanding Data Quality Challenges
Data quality issues are pervasive in many organizations, hindering effective data integration and analysis. These issues encompass a wide range of problems, from inconsistencies in data formats and structures to inaccuracies in values and missing data points. Identifying and understanding these challenges is the first step towards implementing effective solutions and ensuring reliable data use across various business functions.
Different data sources often employ disparate formats and structures, making them incompatible for seamless integration. This incompatibility can manifest in variations in data types, naming conventions, or even the units of measurement used. These differences can lead to errors in data processing and analysis, ultimately affecting the accuracy and reliability of insights derived from the integrated data.
Identifying Inconsistent Data Formats
A significant data quality challenge is the presence of inconsistent data formats across different data sources. This inconsistency arises from various factors, including legacy systems, different data entry practices, and disparate data collection methods. These inconsistencies can lead to difficulties in data transformation and integration, requiring significant effort to normalize and standardize the data before it can be used effectively.
For instance, a customer's address might be stored in different formats across different systems, leading to difficulties in identifying and matching customers across various databases. Ensuring consistent data formats is crucial for smooth data integration and analysis.
Dealing with Inaccurate Data Values
Inaccurate data values represent another critical data quality issue that can significantly impact the reliability of analysis. Data entry errors, faulty measurement devices, or outdated information can all contribute to inaccurate data values. These inaccuracies can lead to flawed conclusions and potentially detrimental business decisions.
Identifying and correcting inaccurate data values is a crucial step in ensuring data quality. Robust data validation procedures and data cleansing techniques are essential to mitigate the impact of inaccuracies and ensure the reliability of the data used for decision-making.
Addressing Missing Data Points
Missing data points are a frequent occurrence in many datasets. These missing values can stem from various factors, including data entry errors, incomplete surveys, or technical failures during data collection. The presence of missing data can lead to incomplete or biased analyses and hinder the ability to draw accurate conclusions.
Strategies to address missing data include imputation techniques, which involve estimating missing values based on existing data patterns, and removal of records with missing values, depending on the nature and extent of the missing data. Careful consideration of the impact of missing data on the analysis is essential for effective data integration.
Implementing Data Validation Rules
Data validation rules are crucial for maintaining data quality throughout the data integration process. These rules define acceptable values, formats, and constraints for data elements, ensuring consistency and accuracy. By implementing robust validation rules, organizations can proactively identify and correct data errors before they propagate through the system.
Implementing data validation at various stages of the data pipeline, from data entry to data transformation, can catch and correct errors early, saving time and resources. These rules can be automated to ensure consistent application across different data sources and processes.
Ensuring Data Governance and Standards
Establishing clear data governance policies and standards is essential for maintaining data quality across the organization. These policies define roles, responsibilities, and procedures for data management, ensuring data accuracy and consistency. A well-defined data governance framework helps to maintain data integrity and traceability, enabling organizations to understand the source and history of their data.
Establishing clear data standards, including data definitions and naming conventions, ensures consistency and interoperability across different data sources. This approach fosters a culture of data quality, enabling data professionals to work effectively with reliable and trustworthy data, leading to more accurate and reliable insights.

Read more about Data Integration Challenges in Mergers & Acquisitions for Supply Chains










Hot Recommendations
- AI for dynamic inventory rebalancing across locations
- Visibility for Cold Chain Management: Ensuring Product Integrity
- The Impact of AR/VR in Supply Chain Training and Simulation
- Natural Language Processing (NLP) for Supply Chain Communication and Documentation
- Risk Assessment: AI & Data Analytics for Supply Chain Vulnerability Identification
- Digital twin for simulating environmental impacts of transportation modes
- AI Powered Autonomous Mobile Robots: Enabling Smarter Warehouses
- Personalizing Logistics: How Supply Chain Technology Enhances Customer Experience
- Computer vision for optimizing packing efficiency
- Predictive analytics: Anticipating disruptions before they hit